

เมื่อยักษ์ชนจิ๋ว ใครจะอยู่ใครจะไป
ในโลกของปัญญาประดิษฐ์ (AI) ทุกวันนี้ Large Language Models (LLMs) เปรียบเสมือนยักษ์ใหญ่ที่ครองบัลลังก์ ไม่ว่าจะเป็นการสร้างบทความ ตอบคำถาม หรือแม้แต่เขียนโค้ด โมเดลเหล่านี้ก็ทำได้ดีจนน่าทึ่ง แต่ลองคิดดูสิครับ ยักษ์ใหญ่เหล่านี้ต้องใช้พลังงานและพื้นที่เท่าไหร่? โมเดลเหล่านี้อาจจะเก่งกาจ แต่ก็เทอะทะ ช้า และสิ้นเปลือง
แล้วถ้าเรามีทางเลือกอื่นล่ะ? ทางเลือกที่เป็นเหมือนดาวรุ่งดวงใหม่ คล่องตัวกว่า ประหยัดกว่า และอาจจะฉลาดกว่าในบางเรื่อง?
นั่นคือ Small Language Models (SLMs)
SLMs คือใคร? จิ๋วแต่แจ๋วมีอยู่จริง
SLMs ก็คือโมเดลภาษาเหมือนกันกับ LLMs นั่นแหละครับ แต่มีขนาดเล็กกว่ามาก ลองนึกภาพว่า LLMs เป็นเหมือนคอมพิวเตอร์ระดับซูเปอร์ไซส์ที่ทรงพลังแต่ก็เทอะทะ ส่วน SLMs ก็เหมือนกับสมาร์ทโฟนที่อาจจะไม่ได้แรงเท่า แต่ก็คล่องตัวและพกพาสะดวกกว่าเยอะ ทำให้เหมาะกับการใช้งานในหลาย ๆ สถานการณ์ที่เราไม่ได้ต้องการพลังประมวลผลขนาดนั้น
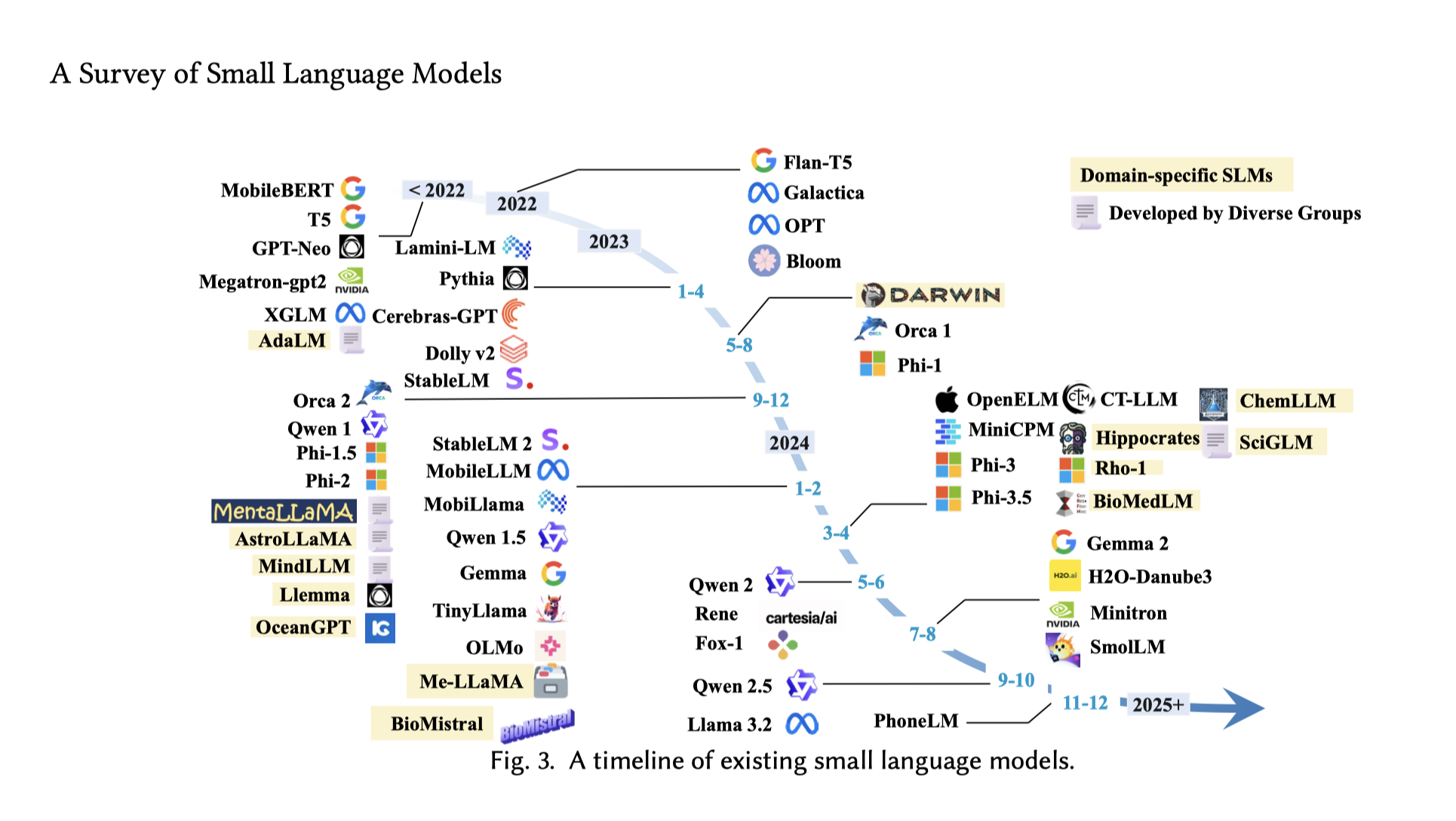
(ภาพจากเปเปอร์ อ้างอิง)
ทำไมต้อง SLMs? 5 เหตุผลที่ทำให้พวก SLMs มาแรง
ทำไม SLMs ถึงน่าสนใจ? โมเดลเหล่านี้มีดีอะไรที่ทำให้หลายคนเริ่มหันมามอง?
- ประหยัดพลังงานและพื้นที่: SLMs เหมือนนักวิ่งระยะสั้น โมเดลเหล่านี้อาจจะไม่ใช่คนที่วิ่งได้อึดที่สุด แต่ก็วิ่งได้เร็วกว่าเยอะในระยะทางสั้น ๆ โมเดลเหล่านี้ใช้พลังงานน้อยกว่า ต้องการพื้นที่ในการจัดเก็บน้อยกว่า และประมวลผลได้เร็วกว่า LLMs มาก ทำให้เหมาะกับการใช้งานบนอุปกรณ์ขนาดเล็กอย่างมือถือหรืออุปกรณ์ IoT
- เป็นส่วนตัวและปลอดภัยกว่า: ลองคิดดูว่าข้อมูลส่วนตัวของเรา ไม่ว่าจะเป็นข้อความแชท ข้อมูลสุขภาพ หรือข้อมูลทางการเงิน ถูกประมวลผลอยู่บนมือถือของเราเอง โดยไม่ต้องส่งไปที่ไหน นั่นแหละครับคือสิ่งที่ SLMs ทำได้ โมเดลเหล่านี้ช่วยให้ข้อมูลของเราปลอดภัยและเป็นส่วนตัวมากขึ้น
- ปรับแต่งได้ตามใจ: SLMs เหมือนดินน้ำมัน เราสามารถปั้นแต่งโมเดลเหล่านี้ให้เป็นอะไรก็ได้ที่เราต้องการ ไม่ว่าจะเป็นผู้ช่วยส่วนตัว นักเขียนโค้ด หรือผู้เชี่ยวชาญเฉพาะทาง SLMs ก็สามารถปรับตัวให้เข้ากับงานต่าง ๆ ได้ง่ายกว่า LLMs
- คุ้มค่าสบายกระเป๋า: การสร้างและใช้งาน LLMs เหมือนกับการสร้างยานอวกาศ มันต้องใช้เงินและทรัพยากรจำนวนมหาศาล แต่ SLMs เหมือนกับการสร้างรถยนต์ มันถูกกว่า เร็วกว่า และใช้งานได้หลากหลายกว่า ทำให้ SLMs เป็นทางเลือกที่คุ้มค่ากว่าสำหรับหลาย ๆ องค์กรและนักพัฒนา
- ตอบสนองได้ทันใจ: ในโลกที่ทุกอย่างต้องรวดเร็วทันใจ SLMs คือฮีโร่ โมเดลเหล่านี้ตอบสนองได้เร็วกว่า LLMs มาก ทำให้เหมาะกับแอปพลิเคชันที่ต้องการความเร็วในการตอบสนองสูง
SLMs vs. LLMs: เพื่อนร่วมงานที่เก่งกันคนละด้าน
หลายคนอาจจะสงสัยว่า SLMs กับ LLMs ต่างกันยังไง? โมเดลเหล่านี้เป็นคู่แข่งกันหรือเปล่า?
จริง ๆ แล้ว SLMs กับ LLMs ไม่ใช่คู่แข่งกันโดยตรง โมเดลทั้งสองประเภทเป็นเหมือนเพื่อนร่วมงานที่เก่งกันคนละด้าน
LLMs อาจจะเก่งในการทำงานที่ซับซ้อนและต้องการความรู้รอบด้าน ในขณะที่ SLMs เก่งในการทำงานที่เฉพาะเจาะจงและต้องการความรวดเร็ว
ลองนึกภาพว่า LLMs เป็นเหมือนอาจารย์มหาวิทยาลัยที่รอบรู้ในทุก ๆ ด้าน ส่วน SLMs เป็นเหมือนผู้เชี่ยวชาญเฉพาะทางที่เก่งในสาขาของตัวเอง เราต้องการทั้งสองคน อาจารย์ที่ให้ความรู้พื้นฐานและผู้เชี่ยวชาญที่ให้คำแนะนำเชิงลึก
สถาปัตยกรรมของ SLMs: เบื้องหลังความฉลาดของจิ๋ว
SLMs มีสถาปัตยกรรมที่หลากหลาย แต่ส่วนใหญ่มักมีพื้นฐานมาจาก Transformer ซึ่งเป็นสถาปัตยกรรมที่ได้รับความนิยมอย่างมากในด้าน NLP
Transformer: สมองกลที่เข้าใจภาษา
Transformer เปรียบเสมือนสมองกลที่ช่วยให้โมเดลเข้าใจความหมายของภาษา สถาปัตยกรรมนี้มีส่วนประกอบหลัก ๆ ดังนี้:
- Self-Attention: กลไกที่ช่วยให้โมเดลมองเห็นความสัมพันธ์ระหว่างคำต่าง ๆ ในประโยค
- Multi-Head Attention: เหมือนกับการมีผู้ช่วยหลายคนคอยช่วยกันวิเคราะห์ข้อมูล
- Feedforward Network: ส่วนที่ช่วยให้โมเดลเรียนรู้ข้อมูลที่ซับซ้อน
- Positional Encoding: ตัวช่วยจำตำแหน่งของคำในประโยค
- Layer Normalization: ตัวช่วยให้โมเดลเรียนรู้ได้เร็วและมีเสถียรภาพมากขึ้น
สถาปัตยกรรมทางเลือก: เมื่อความเร็วและความประหยัดเป็นสิ่งสำคัญ
นอกจาก Transformer แล้ว ก็ยังมีสถาปัตยกรรมทางเลือกอื่น ๆ ที่น่าสนใจ โดยเฉพาะเมื่อเราต้องการ SLMs ที่เร็วและประหยัดทรัพยากร:
- Mamba: สถาปัตยกรรมที่ใช้ State Space Models (SSMs) ซึ่งมีประสิทธิภาพในการจัดการกับข้อมูลที่เป็นลำดับ (เช่น ข้อความ) และมีความเร็วในการประมวลผลสูง
- Hymba: สถาปัตยกรรมลูกผสมที่รวมเอาจุดเด่นของ Transformer และ Mamba เข้าด้วยกัน
- xLSTM: สถาปัตยกรรมที่พัฒนามาจาก LSTM ซึ่งเป็น RNN รูปแบบหนึ่ง โดยมีการปรับปรุงให้มีประสิทธิภาพมากขึ้นในการจัดการกับข้อมูลที่เป็นลำดับยาว
ฝึกฝน SLMs ให้เก่งกาจ: เคล็ดลับวิชาที่ต้องรู้
การฝึกฝน SLMs ให้เก่งกาจเหมือนกับการฝึกฝนนักกีฬา มันต้องใช้ทั้งพรสวรรค์ การฝึกฝน และกลยุทธ์ที่เหมาะสม
Pre-training: สร้างรากฐานที่แข็งแกร่ง
การ Pre-training คือการฝึกฝน SLMs บนชุดข้อมูลขนาดใหญ่เพื่อให้โมเดลเหล่านี้เรียนรู้พื้นฐานของภาษา เหมือนกับการสอนเด็กให้รู้จักตัวอักษร คำศัพท์ และไวยากรณ์
Fine-tuning: เจาะจงให้เชี่ยวชาญ
การ Fine-tuning คือการปรับแต่ง SLMs ที่ได้รับการ Pre-training แล้วให้เชี่ยวชาญในงานเฉพาะ เหมือนกับการฝึกฝนนักกีฬาให้เก่งในกีฬาประเภทใดประเภทหนึ่ง
Decoding Strategies: กลยุทธ์ในการสร้างสรรค์
Decoding Strategies คือวิธีการที่ใช้ในการสร้างข้อความจาก SLMs เหมือนกับการเลือกคำที่เหมาะสมในการแต่งเพลงหรือเขียนบทกวี
ดึงพลังจากยักษ์: การดึง SLMs จาก LLMs
แทนที่จะฝึกฝน SLMs ตั้งแต่เริ่มต้น เราสามารถ "ดึง" โมเดลเหล่านี้ออกมาจาก LLMs ได้ เหมือนกับการถ่ายทอดความรู้จากรุ่นพี่สู่รุ่นน้อง
เทคนิคหลักในการดึง SLMs จาก LLMs ได้แก่:
- Pruning: การตัดแต่ง LLMs เพื่อให้เล็กลงและเร็วขึ้น
- Destilación de conocimientos: การถ่ายทอดความรู้จาก LLMs ไปยัง SLMs
- Quantization: การลดความแม่นยำในการคำนวณของ LLMs เพื่อให้ SLMs ประมวลผลได้เร็วขึ้น
สุดยอดเคล็ดลับ: เทคนิคขั้นสูงในการพัฒนา SLMs
เพื่อทำให้ SLMs เก่งกาจยิ่งขึ้น นักวิจัยได้พัฒนาเทคนิคขั้นสูงมากมาย:
- Innovative Training Methods for Small Language Models from Scratch: วิธีการฝึกฝน SLMs ตั้งแต่เริ่มต้นที่เน้นการออกแบบสถาปัตยกรรม การสร้างชุดข้อมูล และการใช้วิธีการ Optimization ที่เหมาะสม
- Supervised Fine-Tuning (SFT) for Enhancing SLM performance: การปรับแต่ง SLMs ด้วยข้อมูลที่มีป้ายกำกับเพื่อเพิ่มประสิทธิภาพในการทำงานเฉพาะ
- Data Quality in Knowledge Distillation (KD): การให้ความสำคัญกับคุณภาพของข้อมูลที่ใช้ในการ Knowledge Distillation โดยเฉพาะข้อมูลที่สร้างจาก LLMs
- Distillation Techniques for Enhancing SLM Performance: เทคนิคเฉพาะในการ Knowledge Distillation ที่ออกแบบมาเพื่อแก้ไขปัญหาที่เกิดขึ้นเมื่อถ่ายทอดความรู้จาก LLMs ไปยัง SLMs
- Performance Improvement through Quantization: วิธีการ Quantization ที่ออกแบบมาเพื่อลดผลกระทบต่อประสิทธิภาพของ SLMs
- Techniques in LLMs Contributing to SLMs: การนำเทคนิคที่ใช้ใน LLMs มาปรับใช้กับ SLMs เพื่อเพิ่มประสิทธิภาพ
SLMs ทำอะไรได้บ้าง? การประยุกต์ใช้งานที่หลากหลาย
SLMs ไม่ได้เก่งแค่เรื่องประหยัด โมเดลเหล่านี้ยังทำงานได้หลากหลาย:
- Question-Answering (QA): SLMs สามารถเป็นผู้ช่วยอัจฉริยะที่ตอบคำถามได้แม่นยำและรวดเร็ว
- Coding: SLMs สามารถเป็นคู่หูในการเขียนโค้ด ช่วยแนะนำ เติมโค้ด และตรวจจับข้อผิดพลาด
- Recommender Systems: SLMs สามารถปรับปรุงระบบแนะนำสินค้าและบริการให้ตรงใจผู้ใช้มากขึ้น
- Web Search: SLMs สามารถช่วยให้การค้นหาเว็บแม่นยำและตรงกับความต้องการของผู้ใช้มากขึ้น
- Mobile-device: SLMs สามารถทำงานบนมือถือได้ ช่วยให้เราควบคุมอุปกรณ์ ใช้แอปพลิเคชัน และทำงานอื่น ๆ ได้สะดวกขึ้น (เช่น แอปฯสุขภาพที่ติดตามอาการได้เรียลไทม์โดยไม่ต้องส่งข้อมูลขึ้นคลาวด์)
SLMs ทำงานบนมือถือและ Edge Devices ได้อย่างไร? เทคนิคการปรับใช้ที่ต้องรู้
การนำ SLMs ไปใช้บนมือถือและ Edge Devices นั้นไม่ใช่เรื่องง่าย เพราะอุปกรณ์เหล่านี้มีข้อจำกัดด้าน Memory และพลังงาน แต่ก็มีเทคนิคที่ช่วยให้เราทำได้:
- Memory Efficiency Optimization: การทำให้ SLMs ใช้ Memory น้อยลง
- Runtime Efficiency Optimization: การทำให้ SLMs ประมวลผลได้เร็วขึ้น
SLMs มีกี่ประเภท? เจาะลึก Generic และ Domain-Specific SLMs
SLMs ไม่ได้มีแค่แบบเดียว โมเดลเหล่านี้แบ่งออกเป็น 2 ประเภทหลัก:
- Generic-Domain SLMs: SLMs ที่ได้รับการฝึกฝนให้มีความรู้ทั่วไปในหลาย ๆ ด้าน
- Domain-Specific SLMs: SLMs ที่ได้รับการฝึกฝนให้มีความรู้เฉพาะทางในโดเมนใดโดเมนหนึ่ง (เช่น BioMedLM สำหรับการแพทย์)
SLMs และ LLMs: คู่หูที่ลงตัว
SLMs และ LLMs ไม่ได้เป็นคู่แข่งกัน แต่เป็นเหมือนคู่หูที่ช่วยเสริมสร้างซึ่งกันและกัน
- SLMs ช่วย LLMs: SLMs สามารถช่วยให้ LLMs ทำงานได้ดีขึ้นในด้านต่าง ๆ เช่น การสร้างข้อความที่น่าเชื่อถือ การดึงข้อมูลที่เกี่ยวข้อง การปรับแต่งโมเดล และการประเมินประสิทธิภาพ
- LLMs ช่วย SLMs: LLMs สามารถให้ข้อมูลเพิ่มเติมแก่ SLMs และช่วยในการสร้างชุดข้อมูลสำหรับการฝึกอบรม SLMs
ความน่าเชื่อถือ: หัวใจสำคัญของ SLMs
SLMs จะต้องมีความน่าเชื่อถือ โดยเฉพาะเมื่อนำไปใช้งานในสถานการณ์ที่ต้องการความถูกต้องและความปลอดภัยสูง
ประเด็นสำคัญที่เกี่ยวข้องกับความน่าเชื่อถือของ SLMs ได้แก่:
- Robustness
- Privacidad
- Reliability
- Safety
- Fairness
สรุป: SLMs อนาคตของ AI ที่ยั่งยืนและเข้าถึงได้
Small Language Models (SLMs) ไม่ใช่แค่เทรนด์ฉาบฉวย แต่เป็นคลื่นลูกใหม่ที่จะเปลี่ยนโฉมหน้าของ AI โมเดลเหล่านี้คือความหวังในการสร้าง AI ที่ยั่งยืน เข้าถึงได้ และเป็นประโยชน์ต่อทุกคน ไม่ว่าจะเป็นใคร ที่ไหน หรือมีทรัพยากรมากน้อยแค่ไหน
ในบทความนี้ เราได้สำรวจโลกของ SLMs อย่างละเอียด ตั้งแต่ข้อดีข้อเสียไปจนถึงเทคนิคการพัฒนาและแนวโน้มในอนาคต
เราได้เห็นแล้วว่า SLMs ไม่ได้เป็นแค่ "น้องเล็ก" ของ LLMs แต่เป็นขุมพลังที่ซ่อนอยู่ รอคอยการค้นพบและปลดปล่อย
อนาคตของ AI ไม่ได้ขึ้นอยู่กับแค่การสร้างโมเดลที่ใหญ่ขึ้นและทรงพลังขึ้นเท่านั้น แต่อยู่ที่การสร้างโมเดลที่ฉลาดขึ้น คล่องตัวขึ้น และเป็นมิตรกับผู้ใช้มากขึ้น และ SLMs นี่เองที่จะเป็นกุญแจสำคัญในการไขประตูสู่อนาคตนั้น